当前,云计算、5G、人工智能、虚拟客户体验等各类数字技术正在改变着我们的工作生活和企业的运营方式。在全新的数字经济环境下,无论是企业的研发设计、模拟仿真还是个人的图形处理、视觉优化,都对GPU性能有了更高的要求,企业需要更强劲的GPU性能让响应更加迅速、协作更加高效。作为GPU的发明者和全球图形运算行业领袖,在过去20年时间里,NVIDIA持续对GPU进行创新迭代,在不同领域针对GPU性能、软硬件设计、功能优化,从最早的Kepler架构到Maxwel、Pascal、Turing以及最新的Ampere架构,NVIDIA为各行各业的用户带来性能上的强劲提升。
特别是在工程设计与仿真领域,随着模型规模越来越大,产品创新方案需求越来越快,传统的CPU已经无法满足现代3D图形应用程序的复杂计算任务,对于GPU加速的计算需求越来越多。以CFD(Computational Fluid Dynamics,计算流体仿真)为例,网格的合理设计和高质量生成是CFD计算的前提条件,也是影响CFD计算结果的最主要的决定性因素之一,借助于GPU加速计算所提供的非凡应用程序性能,能将CFD程序计算密集部分的工作负载转移到GPU,使CFD计算速度明显加快。
由于GPU的选择将从根本上决定CFD分析过程的体验,如何更有效结合CFD模型特点和GPU硬件加速,进而充分释放并行计算能力实现极致加速成为非常重要的研究课题。本文将分享基于Altair的CFD软件和Nvidia GPU硬件相结合的案例评测,供CFD工程师选择GPU时参考。
评测案例一:通用跑车和Altair CX-1在DGX-1的加速情况
软件环境介绍——Altair ultraFluidX™是一款用于超快预测乘用车、轻型卡车、重型车辆以及赛车应用的空气动力特性的仿真分析软件,它基于格子玻尔兹曼(LBM)技术,具有瞬态仿真、高效并行以及低数值耗散的特点。同时,Altair ultraFluidX在开发之初就是基于GPU硬件优化,相对于传统的CPU求解器,效率有不小提升,尤其针对瞬态计算而言,可以高效快速地获得准确地仿真结果。本案例软件运行环境基于Altair ultraFluidX 2019版本。
硬件环境介绍——测试模型运行在DGX-1系统与2颗Intel Xeon E5-2698 v4,其主频是2.2GHz,CPU核心数量20,驱动410.79,RAM是512GB;DGX OS 4.0.4;GPU选择8块NVIDIA V100 32GB并采用NVLink的连接方式,NVIDIA V100采用NVIDIA Volta架构,在单个GPU中提供高达32个CPU的性能,CFD工程师可以花费更少的时间优化内存使用,更快更高效地获得CFD分析结果。需要指出的是,NVLink是一种高带宽且节能的互联技术,能够在CPU-GPU和GPU-GPU之间实现超高速的数据传输,这项技术的数据传输速度是传统PCIe3.0速度的多倍,能够大幅提升应用程序的处理速度,并使得高密集度而灵活的加速运算服务器成为了可能。

NVIDIA V100
:对于一款跑车而言,符合空气动力学的车身造型设计尤为关键。借助空气动力学CFD工具,工程师可以在跑车下压力与最低空气阻力之间找到一个完美的平衡点,以实现高效节能、减少噪音、提高车辆的平顺性和行驶稳定性等目标。本测试选择流体单元约3600万的通用跑车和拥有约2.3亿流体单元的Altair CX-1概念跑车为模型进行外部空气动力学仿真,其中Altair CX-1具有产品级别的复杂性和细节,通过这两种模型在DGX-1系统下GPU加速的相对性能测试,比较NVIDIA V100所带来的运算性能的提升。
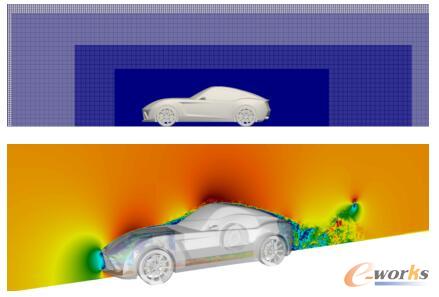
流体单元约3600万的通用跑车模型
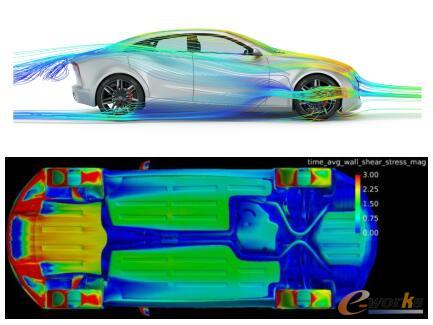
约2.3亿流体单元的Altair CX-1跑车模型
:数据表明,通用跑车外部空气动力学仿真分析在1块、2块、4块、6块、8块GPU加速下,相对性能的数值分别是1、1.8、3.2、4、4.9;基于Altair CX-1跑车外部空气动力学仿真分析在4块、6块、8块GPU加速下,相对性能的数值分别是4、5.7、7.3。测试结果也表明,采用Altair ultraFluidX软件进行外部空气动力学仿真分析,并由NVIDIA V100提供加速支持,可以获得接近线性GPU并行运算性能。
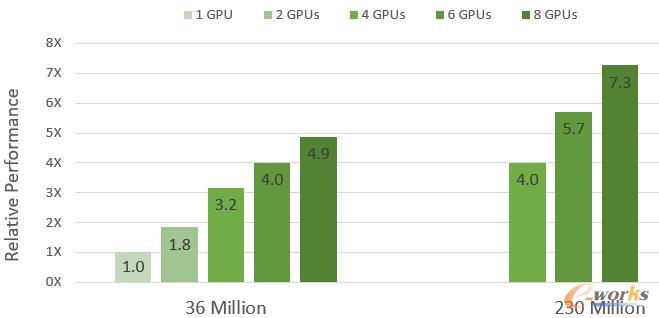
两种模型在DGX-1系统下GPU加速的相对性能
(注:相对性能根据模型MNUPS(每秒更新百万节点)性能计算)
——与评测案例一的软件环境相同,本案例还是选择在基于Altair ultraFluidX 2019版本下运行。
硬件环境介绍——测试模型在EGX服务器上使用2颗Intel Xeon Gold 6126处理器、12核CPU、驱动430.14,384GB RAM、RHEL 7.6、带NVLink的8块RTX 8000显卡进行测试。RTX 8000由NVIDIA Turing架构和NVIDIA RTX平台提供支持,借助RTX 8000,CFD工程师可以处理大型复杂的光线追踪和可视化计算负载。

RTX 8000
:本次测试仍选择流体单元约3600万的通用跑车和拥有约2.3亿流体单元的Altair CX-1概念跑车为模型进行外部空气动力学仿真,比较两种模型在EGX服务器下有无采用NVLINK连接时的相对性能数值。
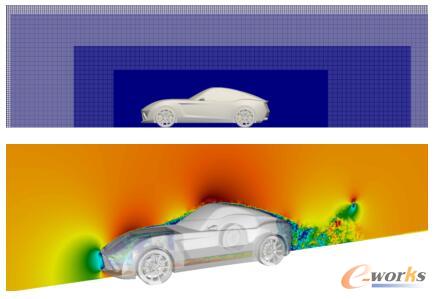
流体单元约3600万的通用跑车模型

约2.3亿流体单元的Altair CX-1跑车模型
:在未采用NVLink连接时,通用跑车外部空气动力学仿真分析在1块、2块、4块、8块GPU加速下,相对性能的数值分别是1、1.9、2.9、3.1;在采用NVLink连接后,通用跑车外部空气动力学仿真分析在1块、2块、4块、8块GPU加速下,相对性能的数值分别是1、1.9、3.2、4。在未采用NVLink连接时,基于Altair CX-1跑车外部空气动力学仿真分析在4块、8块GPU加速下,相对性能的数值分别是4、6.1;在采用NVLink连接后,基于Altair CX-1跑车外部空气动力学仿真分析在4块、8块GPU加速下,计算性能的数值分别是4.1、7.3。测试结果也表明,采用Altair ultraFluidX软件进行外部空气动力学仿真分析,并由RTX 8000提供加速支持,通过采用NVLink连接与接近线性的GPU运算,可使计算性能提升高达20%以上。
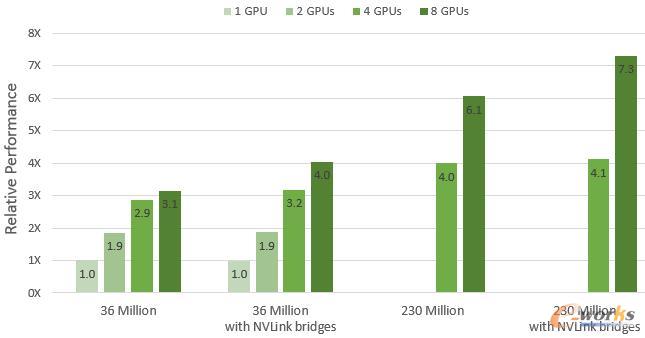
两种模型在EGX服务器下GPU加速的相对性能
(注:相对性能根据模型MNUPS(每秒更新百万节点)性能计算)
——Altair nanoFluidX™是一款基于粒子的流体动力学(SPH)仿真工具,用于预测运动轨迹复杂的几何结构周围的流体,包括预测含旋转轴/齿轮的动力总成系统中的润滑情况并分析系统中各组件的受力和力矩,以及处于瞬变运动的储罐中流体的晃动情况。该软件支持GPU加速,助力对真实几何结构进行高性能仿真。本案例软件运行环境基于Altair nanoFluidX 2020.0版本。
硬件环境介绍——测试模型在EGX服务器上使用2颗Intel Xeon Gold 6126处理器、12核CPU、驱动440.44,384GB RAM、2TB M.2 NVMe、RHEL 7.5、4块RTX 8000显卡进行测试。由于本次软件使用的是Altair nanoFluidX,其计算是由一系列的流体粒子的相互作用完成,在不同的数据上执行相同的程序,恰是RTX 8000所擅长的。

RTX 8000
:在新能源汽车中,减速机是一种相对精密的机械,使用它的目的是降低转速,增加转矩;在航空应用中,齿轮箱是飞机传动系统中的一个重要组成部件,直接影响飞机的动力性、传动稳定性以及传动效率。长期以来,减速机和齿轮箱结构复杂,预测它们的润滑情况并分析系统中各组件的受力和力矩,以及内部油液和空气处于瞬时变化的流场分析,往往需要消耗大量的计算资源和时间。本轮测试选择Altair新能源车减速器和航空齿轮箱为模型,其中,Altair新能源车减速器总计约有1200万流体粒子,航空齿轮箱总计约有2670万流体粒子,两个模型迭代步数都设置为10000个时间步,通过这两个模型在EGX服务器下GPU加速的相对性能测试,比较RTX8000所带来的计算性能的提升。

Altair新能源车减速器模型

航空齿轮箱模型
:数据表明,Altair新能源车减速器仿真分析在1块、2块、4块GPU加速下,相对性能数值分别是1、1.8、3.1;航空齿轮箱仿真分析在1块、2块、4块GPU加速下,相对性能数值分别是1、1.9、3.7。计算结果也表明,采用Altair nanoFluidX软件进行流体仿真分析,并由RTX 8000提供加速支持,可以获得接近线性GPU并行运算性能。
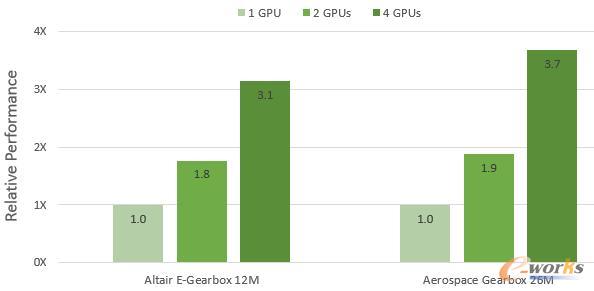
两种模型在EGX服务器下GPU加速的相对性能
(注:相对性能根据Altair nanoFluidX 2020.0版本上算例的平均模型性能(秒/粒子/时间步数)计算)
——与评测案例三的软件环境相同,本案例还是选择在基于Altair nanoFluidX 2020.0版本下运行。
硬件环境介绍——测试模型运行在DGX-1系统与2颗Intel E5-2698 v4处理器、其主频是2.2GHz,CPU核心数量20,驱动410.79,512GB RAM;DGX OS 4.0.4;GPU选择8xNVIDIA V100 32GB与NVLink的连接方式。

NVIDIA V100
:本次测试依然选择Altair新能源车减速器和航空齿轮箱为模型,Altair新能源车减速器总计约有1200万流体粒子,航空齿轮箱总计约有2670万流体粒子,两个模型迭代步数都设置为10000个时间步,比较两种模型在DGX-1下采用NVLink连接时的相对性能数值。

Altair新能源车减速器模型

航空齿轮箱模型
:在采用NVLink连接时,Altair新能源车减速器仿真分析在1块、2块、4块GPU加速下,相对性能数值分别是1、1.7、2.9;航空齿轮箱仿真分析在1块、2块、4块GPU加速下,相对性能数值分别是1、1.8、3.7。计算结果也表明,采用Altair nanoFluidX软件进行流体仿真分析,并由NVIDIA V100提供加速支持,也可获得接近线性GPU并行运算性能。
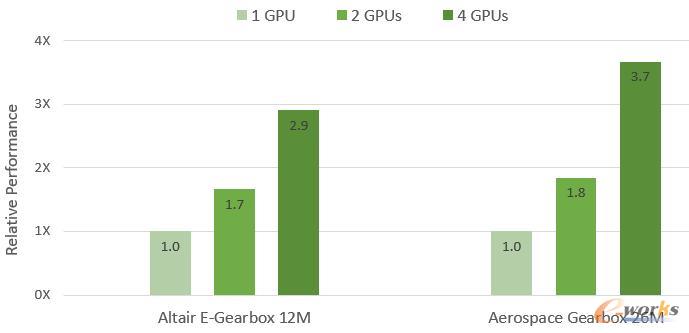
两种模型在DGX-1下GPU加速的相对性能
(注:相对性能根据Altair nanoFluidX 2020.0版本上算例的平均模型性能(秒/粒子/时间步数)计算)
——与评测案例三、四的软件环境相同,本案例还是选择在基于Altair nanoFluidX 2020.0版本下运行。
硬件环境介绍——测试模型运行的硬件环境有两种,一种是在DGX-1系统与2颗Intel E5-2698 v4处理器,驱动410.129,512GB RAM,DGX OS 4.0.7,8块16GB的NVIDIA V100;第二种是在DGX-A100和2颗AMD EPYC 7742处理器,驱动450.51,1 TB RAM,DGX OS 4.99.11,GPU选择8块40GB的NVIDIA A100。

NVIDIA V100

NVIDIA A100
:本次选择航空齿轮箱为测试模型,总计约有2670万流体粒子,迭代步数为10000个时间步,比较该模型在DGX-A100和DGX-1下的相对性能数值。

航空齿轮箱模型
:数据表明,在DGX-1硬件环境下,航空齿轮箱仿真分析在1块、2块、4块、8块NVIDIA V100加速下,相对性能数值分别是1、1.6、3.3、6;在DGX-A100硬件环境下,航空齿轮箱仿真分析在1块、2块、4块、8块NVIDIA A100加速下,相对性能数值分别是1.2、2.1、4.2、7.4。由此结果可知,采用Altair nanoFluidX软件进行流体仿真分析,在DGX-A100硬件环境下比在DGX-1硬件环境下GPU加速快30%。这也从侧面反映了NVIDIA A100可以为CFD HPC提高出色的GPU加速。
总结
当前,CFD工程师面临产品复杂度更高、运行环境复杂多变等挑战,需要强大的计算能力来满足仿真和分析复杂工程设计的密集多线程要求,而像Altair ultraFluidX、Altair nanoFluidX这种拥有先进CFD算法的工具,本身对于显卡也有较高的要求,NVIDIA V100、RTX 8000、NVIDIA A100等产品,具备优异的追踪渲染性能以及加速计算专用处理单元,CFD工程师们可以在预处理、求解以及后处理的流程中获取GPU的出色性能加持,加快仿真迭代速度。
e-works认为,NVIDIA GPU加速流体仿真应用势在必行。NVIDIA GPU的并行处理能力使其能够将复杂的计算任务细分成数以千计的,可并行处理的小任务。这个能力使CFD工程师能够以比现在快几个数量级的速度解决全球最具挑战性的计算问题。利用NVIDIA GPU加速,可以彻底改变传统CFD计算研究工作的面貌,为不同行业的企业带来前所未有的创新变革。
